Automatyczne kopiowanie na dysk Yandex. Utwórz kopię zapasową danych na Yandex.Disk dzięki nowej poręcznej kopii zapasowej. Klasyczne funkcje aplikacji wbudowane w Windows
Yandex.Disk jest jedną z niewielu usług Yandex, których częścią jest oprogramowanie na pulpit. Jednym z najważniejszych elementów jest algorytm synchronizacji plików lokalnych z ich kopią w chmurze. Ostatnio musieliśmy to całkowicie zmienić. Jeśli stara wersja z trudem przetrawiała nawet kilkadziesiąt tysięcy plików, a ponadto nie reagowała wystarczająco szybko na niektóre „złożone” działania użytkownika, nowa wersja, wykorzystująca te same zasoby, radzi sobie z setkami tysięcy plików.
Możesz pobrać go ze sklepu z grami i wypróbować za darmo, nie płacąc ani grosza. Ta usługa jest naprawdę bardzo łatwa w użyciu. Jest wyposażony w kilka dodatkowych funkcji, a jedna z nich to kserokopia, która pozwala automatycznie przesyłać dowolne zdjęcie zrobione z telefonu do chmury, a druga to udostępnianie folderów, które pozwala udostępniać dowolny folder każdemu. Dzięki potężnym serwerom nigdy nie będziesz mógł przesyłać swoich plików.
Umożliwia przeglądanie historii zmian w twoich dokumentach oraz udostępnianie je znajomym i ich edycja. Ta usługa, jeśli jest bardzo dobra dla tych użytkowników, którzy chcą pobierać w każdej chwili, gdy przechwytują i wyświetlają je na swoim laptopie na komputerze stacjonarnym lub laptopie. Jest najlepszy w użyciu, ponieważ jest bardzo łatwy w użyciu dla każdego użytkownika.
W tym poście powiem ci, dlaczego tak się stało: czego nie mogliśmy przewidzieć, kiedy wymyśliliśmy pierwszą wersję oprogramowania Yandex.Disk i jak stworzyliśmy nową.
Przede wszystkim o samym zadaniu synchronizacji. Technicznie rzecz biorąc, polega na tym, że ten sam zestaw plików znajduje się w folderze Yandex.Disk na komputerze użytkownika i w chmurze. Oznacza to, że działania użytkownika, takie jak zmiana nazwy, usuwanie, kopiowanie, dodawanie i zmiana plików, powinny być synchronizowane automatycznie z chmurą.
To miejsce wystarcza do przechowywania i udostępniania zdjęć i filmów. Bez względu na to, co przesyłasz do chmury za pomocą mega, wszystko to będzie bezpłatne i szyfrowane, a klucz pozostanie wśród użytkowników. Pozwala to na synchronizację obrazów z kamery bezpośrednio z mega chmurą. Ale jeśli potrzebujesz więcej miejsca do przechowywania, istnieją pewne plany. W tej aplikacji są pewne błędy, ale większość użytkowników chętnie korzysta z tej aplikacji.
Każdy webmaster musi mieć kilka kopii zapasowych swojej witryny, jeśli coś pójdzie nie tak. Więc musisz to zrobić utworzyć kopię zapasową wszystkie pliki, a także bazę danych, aby mieć pełną kopię witryny. Więc jakie jest najlepsze miejsce do utrzymania tego powielania?
Dlaczego nie jest tak proste, jak się wydaje na pierwszy rzut oka?
Teoretycznie zadanie może wydawać się dość proste, ale w rzeczywistości mamy do czynienia z różnymi trudnymi sytuacjami. Na przykład osoba zmieniła nazwę folderu na swoim komputerze, wykryliśmy to i wysłaliśmy polecenie do backendu. Jednak żaden z użytkowników nie czeka, aż backend potwierdzi sukces zmiany nazwy. Osoba natychmiast otwiera folder o lokalnej nazwie, tworzy w nim podfolder i na przykład przenosi do niego część plików. Jesteśmy w sytuacji, w której niemożliwe jest natychmiastowe wykonanie wszystkich niezbędnych operacji synchronizacji w chmurze. Najpierw musisz poczekać na zakończenie pierwszej operacji, a dopiero potem możesz kontynuować.Sytuacja może się jeszcze bardziej skomplikować, jeśli kilku użytkowników pracuje z tym samym kontem w tym samym czasie lub jeśli mają udostępniony folder. I zdarza się to dość często w organizacjach korzystających z Yandex.Disk. Wyobraź sobie, że w poprzednim przykładzie, w momencie, gdy otrzymaliśmy potwierdzenie z zaplecza pierwszej zmiany nazwy, inny użytkownik przejmuje i zmienia nazwę tego folderu ponownie. W takim przypadku ponownie nie można natychmiast wykonać czynności, które pierwszy użytkownik wykonał już na swoim komputerze. Folder, w którym w tym czasie pracował lokalnie na backendie, jest już nazywany inaczej.
Dysk to usługa w chmurze, szczególnie popularna wśród rosyjskich użytkowników. 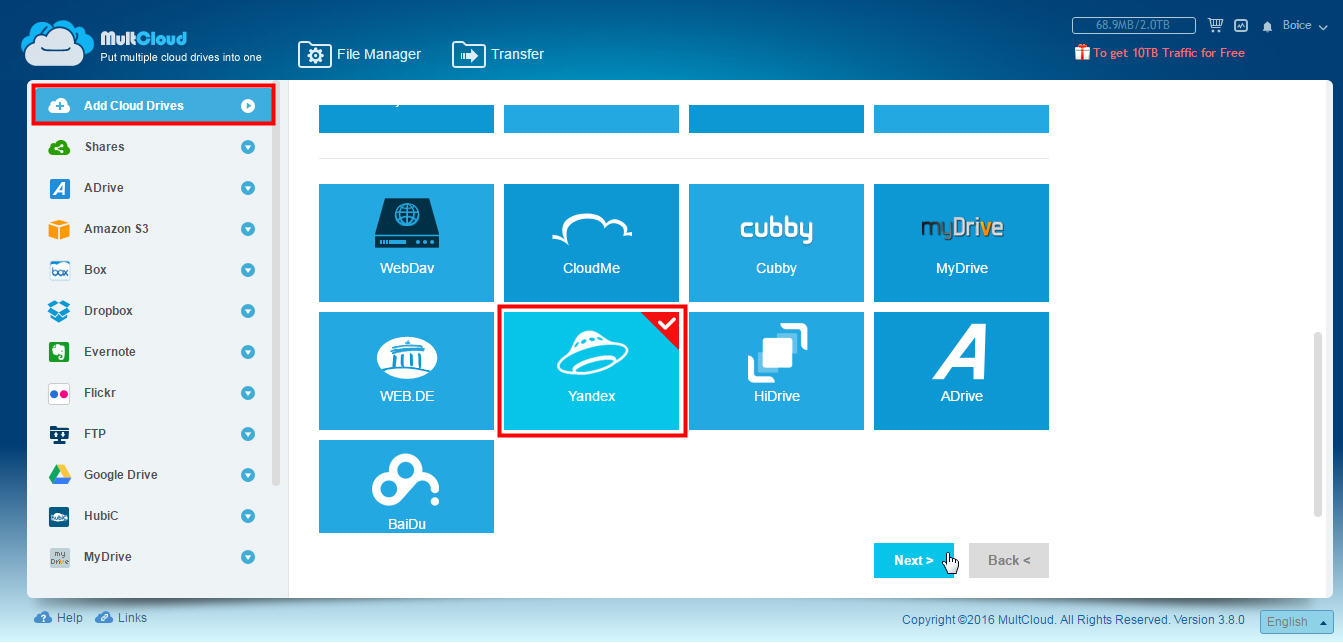
Istnieje wiele opcji, ale z każdej można korzystać tak, jak chcesz. Gdy będziesz gotowy, zobaczysz, że w kolumnie po lewej stronie zostaną wyświetlone różne usługi. Jeśli klikniesz na kogoś lub klikniesz małą strzałkę po prawej, zobaczysz foldery, które znajdują się w każdym z nich. Oczywiście możesz zobaczyć, co zawierają, klikając je dwukrotnie. Możesz także wyświetlić sugerowane opcje, korzystając z menu wyświetlanego prawym przyciskiem myszy w folderze lub pliku.
Czasami plik na komputerze użytkownika nie może zostać nazwany dokładnie tak, jak nazywa się go w chmurze. Może się to zdarzyć, jeśli nazwa zawiera znak, którego nie może używać lokalny system plików, lub jeśli użytkownik zostanie zaproszony do udostępnionego folderu, a on ma własny folder o tej nazwie. W takich przypadkach musimy używać lokalnych aliasów i śledzić ich połączenie z obiektami w chmurze.
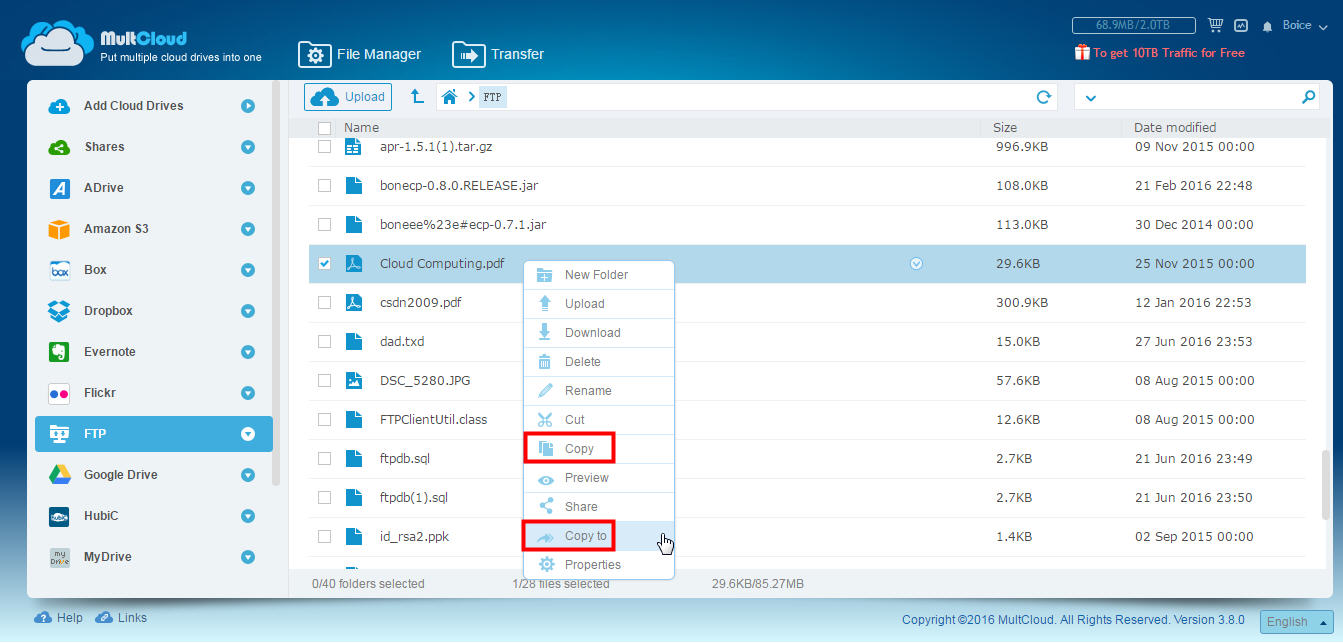
Aby skopiować folder lub plik z eksploratora dokumentów, kliknij go prawym przyciskiem myszy i wybierz polecenie Kopiuj. Natychmiast uruchom okno z usługami pamięci dostępnymi do kopiowania, a ponadto będziemy mieli możliwość wyboru kilku miejsc docelowych bez żadnych komplikacji. Proces jest tak prosty, że przypomina operację wykonywaną bezpośrednio z usługi pamięci masowej.
Zaplanowane kopie zapasowe
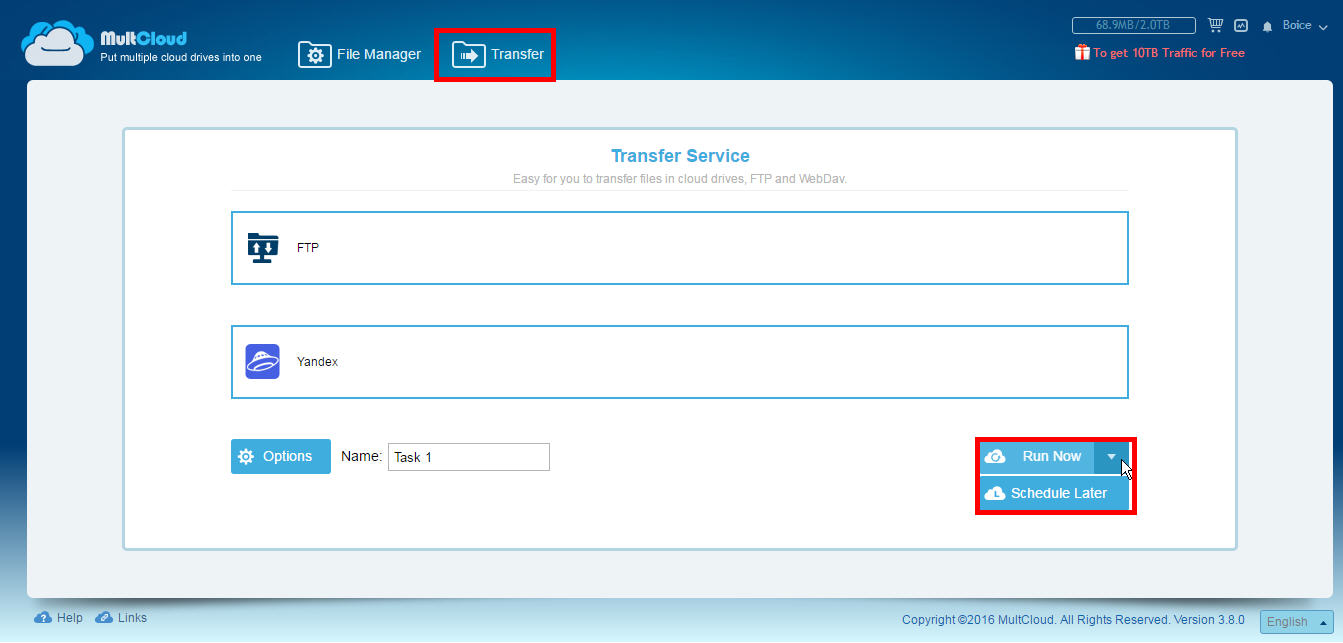
Powinieneś pomyśleć, że podczas tworzenia kopii plik źródłowy pozostanie w innej usłudze, ponieważ jeśli nie chcesz powielać pliku, musisz usunąć plik źródłowy bez obawy o usunięcie go. Innym sposobem przesyłania plików z jednego miejsca do drugiego, a także przydatnym do tworzenia kopii zapasowych, jest użycie przycisku „Top Transfer”, który pozwala wybrać katalog do skopiowania z jednej usługi do drugiej, oprócz ustawiania bardziej zaawansowanych parametrów, takich jak programowanie operacji , nadpisuj, jeśli nastąpiła zmiana, zmień nazwę, wysyłaj powiadomienia e-mail oraz dołącz lub wyklucz pliki.
Poprzednia wersja algorytmu
W poprzedniej wersji oprogramowania komputerowego Yandex.Disk do wyszukiwania zmian zastosowano algorytm porównania drzewa. Żadne inne rozwiązanie w tym czasie nie pozwalało na wyszukiwanie przemieszczeń i zmianę nazwy, ponieważ backend nie miał unikalnych identyfikatorów dla obiektów.W tej wersji algorytmu wykorzystaliśmy trzy główne drzewa: lokalny (lokalny indeks), chmurowy (zdalny indeks) i ostatni zsynchronizowany (stabilny indeks). Ponadto, aby zapobiec ponownemu generowaniu już synchronizowanych operacji synchronizacji, zastosowano dwa dodatkowe drzewa pomocnicze: oczekiwany lokalny i oczekiwany chmurowy (oczekiwany zdalny indeks i oczekiwany lokalny indeks). W tych drzewach pomocniczych oczekiwany stan lokalny system plików i chmury, po wszystkich operacjach synchronizacji, które są już w kolejce.
Parametry planowania pozwalają wykonać operację automatycznie raz, codziennie o określonej godzinie, co tydzień w określone dni i godziny oraz co miesiąc o określonej godzinie i dacie. Aby zobaczyć oczekujące zadania, możemy uzyskać dostęp do menedżera za pomocą przycisku znajdującego się po lewej stronie naszej nazwy u góry.
Teraz, gdy znasz już najłatwiejszy sposób kopiowania plików z jednej pamięci na inną, a nawet na serwer, zapomnij o ponownym przesłaniu plików, aby je pobrać lub użyj klienta stacjonarnego. Celem tego przewodnika jest bezstresowe zarządzanie różnymi usługami.

Procedura porównywania drzew w starym algorytmie była następująca:
- Jeśli oczekiwane drzewo lokalne i drzewo oczekiwane w chmurze są puste, zainicjuj je, kopiując ostatnie drzewo synchronizowane;
- Porównujemy drzewo lokalne z oczekiwaną chmurą i, w oparciu o wyniki porównania poszczególnych węzłów, dodajemy do kolejki operacje synchronizacji w chmurze (tworzenie kolekcji, przesyłanie plików do chmury, przenoszenie i usuwanie w chmurze);
- Dla wszystkich operacji, które są w kolejce w poprzednim kroku, naprawiamy ich przyszły efekt w oczekiwanym drzewie chmury;
- Porównujemy drzewo chmury z oczekiwanym lokalnym i, w oparciu o wyniki porównania poszczególnych węzłów, dodajemy operacje synchronizacji kolejek do lokalnego systemu plików (tworzenie katalogów, pobieranie plików z chmury, przenoszenie i usuwanie lokalnych plików i katalogów);
- Dla wszystkich operacji, które są w kolejce w poprzednim kroku, naprawiamy ich przyszły efekt w oczekiwanym drzewie lokalnym;
- Jeśli jednoczesne operacje z tym samym plikiem lub katalogiem wpadną do kolejki (na przykład przeniesienie pliku do chmury i pobranie tego samego pliku z chmury), wówczas rozwiązujemy konflikt - plik zmienił się w dwóch miejscach;
- Po wykonaniu operacji synchronizacji w chmurze lub w lokalnym systemie plików zapisujemy jej wynik w ostatnim zsynchronizowanym drzewie;
- Gdy kolejka operacji synchronizacji staje się pusta, usuwamy oczekiwane drzewa lokalne i drzewa oczekiwanych chmur. Synchronizacja jest zakończona i nie będziemy ich już potrzebować.
Dlaczego musieliśmy wymyślić nowy algorytm
Głównymi problemami algorytmu porównywania drzew były duże zużycie pamięci i potrzeba porównywania całych drzew nawet przy niewielkich zmianach, co doprowadziło do dużego obciążenia procesora. Podczas przetwarzania zmian nawet jednego pliku użycie pamięci RAM wzrosło o około 35%. Załóżmy, że użytkownik miał 20 000 plików. Następnie, dzięki prostej zmianie nazwy pojedynczego pliku o wielkości 10 KB, zużycie pamięci gwałtownie wzrosło - z 116 MB do 167 MB.Chcieliśmy również zwiększyć maksymalną liczbę plików, z którymi użytkownik może pracować bez problemów. Kilkadziesiąt, a nawet setki tysięcy plików może być na przykład fotografem, który przechowuje wyniki sesji zdjęciowej w Yandex.Disk. To zadanie stało się szczególnie pilne, gdy ludzie mieli okazję kupić dodatkową przestrzeń na Yandex.Disk.
Istnieje kilka sposobów tworzenia kopii zapasowej komputera. Na przykład nie twórz kopii zapasowych plików w sekcji odzyskiwania. Zawsze przechowuj nośniki używane do tworzenia kopii zapasowych w bezpiecznym miejscu, aby uniemożliwić dostęp do twoich plików osobom nieupoważnionym; zalecane jest miejsce ognioodporne inne niż sprzęt.
Aby utworzyć obraz systemu
Możesz również rozważyć szyfrowanie danych z kopii zapasowej.
Obrazy systemowe zawierają wszystkie informacje o komputerze w określonym stanie
Obsługuje różne wersje obrazów systemowych. Możesz przechowywać kilka wersji obrazów systemowych. Na wewnętrznych i zewnętrznych dyskach twardych stare obrazy systemowe zostaną usunięte, gdy na dysku zabraknie miejsca. Aby zaoszczędzić miejsce na dysku, usuń stare obrazy systemu.W rozwoju chciałem też coś zmienić. Debugowanie stara wersja Powodowało to trudności, ponieważ dane o stanach jednego elementu znajdowały się w różnych drzewach.
Do tego czasu na zapleczu pojawiło się id obiektów, przy pomocy których można było efektywniej rozwiązać problem wykrywania ruchów - wcześniej korzystaliśmy ze ścieżek.
Jeśli zapiszesz obrazy systemowe w lokalizacji sieciowej, możesz zapisać tylko najnowsze obrazy systemowe na każdym komputerze. Jeśli masz istniejący obraz systemu komputera i utworzysz nowy dla tego samego komputera, nowy obraz zastąpi istniejący. Jeśli chcesz zapisać istniejący obraz, możesz skopiować go do innej lokalizacji przed utworzeniem nowego obrazu systemu, wykonując następujące kroki.
Utwórz punkt odzyskiwania
Wybierz lokalizację obrazu systemu. . Możesz użyć punktu przywracania, aby przywrócić pliki systemowe komputera we wcześniejszym czasie. Funkcja Przywracanie systemu automatycznie tworzy punkty przywracania co tydzień i gdy komputer wykryje zmiany, na przykład podczas instalacji aplikacji lub sterownika.
Nowy algorytm
Zdecydowaliśmy się zmienić strukturę przechowywania danych i zastąpić trzy drzewa (Indeks lokalny, Indeks zdalny, Indeks stabilny) jednym, co miało zmniejszyć nadmiarowość w głównej strukturze danych. Ponieważ kluczem do drzewa jest ścieżka do elementu systemu plików, w wyniku połączenia ilość pamięci RAM została znacznie zmniejszona.
Jest to sposób na utworzenie punktu przywracania. Aby przeszukać zawartość kopii zapasowej, wybierz Wyszukaj pliki lub Przeszukaj foldery. Podczas wyszukiwania folderów nie można zobaczyć poszczególnych plików w folderze. . Jeśli szukasz plików lub folderów powiązanych z określonym kontem użytkownika, możesz poprawić wyniki wyszukiwania, wprowadzając lokalizację pliku lub folderu w polu wyszukiwania.
Przywróć kopię zapasową wykonaną na innym komputerze
Znajdź pliki, które zostały przywrócone z kopii zapasowej wykonanej na innym komputerze
Jeśli przywrócisz pliki z kopii zapasowej wykonanej na innym komputerze, pliki zostaną przywrócone do folderu pod nazwą użytkownika użytą do utworzenia kopii zapasowej. Jeśli nazwy użytkowników są różne, musisz przewinąć do folderu, w którym pliki zostaną przywrócone.Odmówiliśmy także korzystania z drzew pomocniczych podczas synchronizacji, ponieważ każdy element drzewa w nowej wersji przechowuje wszystkie niezbędne dane. Ta zmiana struktury znacznie uprościła debugowanie kodu.
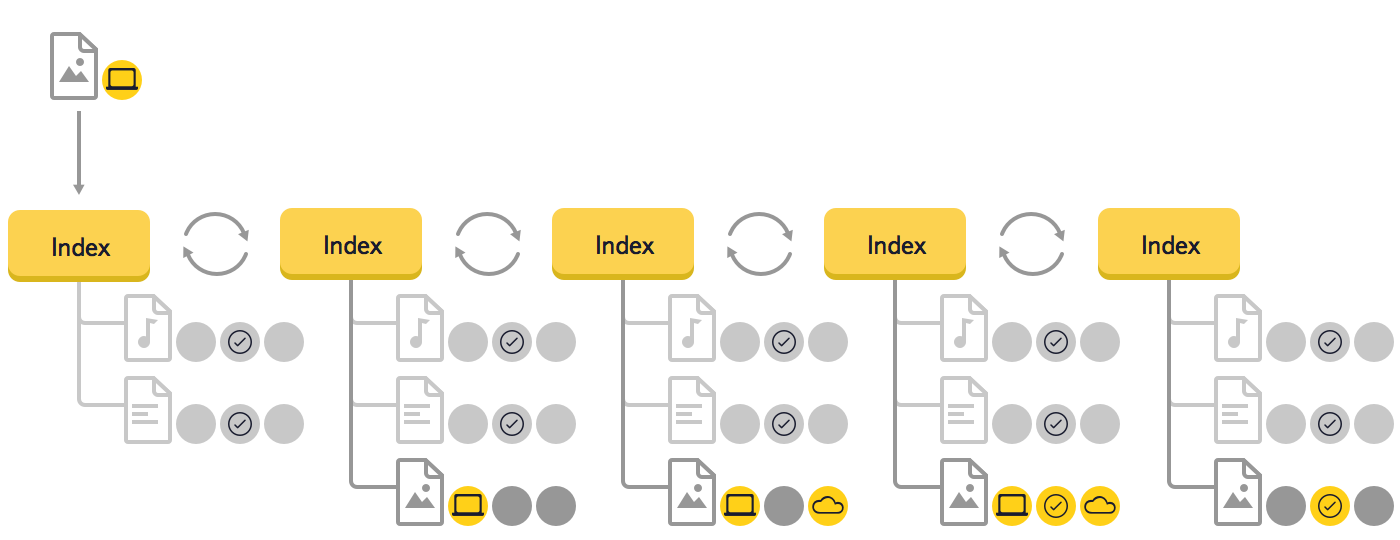
Ponieważ zrozumieliśmy, że to poważna zmiana, stworzyliśmy prototyp, który potwierdził skuteczność nowego rozwiązania. Spójrzmy na przykład zmiany danych w drzewie podczas synchronizacji nowego pliku.
- Po dodaniu przez użytkownika nowego pliku do folderu Dysk, program go wykrył i dodał nowy element do drzewa. Dla tego elementu znany jest tylko jeden stan - lokalny. Ponieważ nie ma stabilnych i zdalnych stanów, nie przydzielono im pamięci;
- Program przesyła plik. Wypychanie pochodzi z chmury potwierdzającej pojawienie się nowego pliku, a do drzewa dodawany jest stan zdalny;
- Porównywane są stany lokalny i zdalny. Ponieważ pasują do siebie, dodawany jest stan stabilny;
- Stany lokalne i zdalne są usuwane. Nie są już potrzebne, ponieważ wszystkie informacje są stabilne.
Maszyny wirtualne i pamięć masowa
Możesz znaleźć odzyskane pliki, wykonując następujące kroki. Kliknij dwukrotnie folder nazwy użytkownika, który został użyty do utworzenia kopii zapasowej. Odzyskane pliki będą znajdować się w różnych folderach w zależności od ich pierwotnego położenia. Przywróć pliki z kopii zapasowej po przywróceniu komputera z kopii zapasowej obrazu systemu.
- Wybierz przycisk Start i wybierz Komputer.
- Kliknij dwukrotnie ikonę dysku, na którym zapisano pliki.
- Kliknij folder Użytkownicy.
- Zobaczysz folder dla każdego konto użytkownik.
Ten przykład pokazuje, że w nowym algorytmie synchronizacji przetwarzane są tylko te elementy i zdarzenia, dane o zmianach, które otrzymano z systemu plików lub chmury, a nie całe drzewo, jak to było wcześniej. W razie potrzeby zostaną przetworzone węzły nadrzędne lub podrzędne (na przykład w przypadku przeniesienia folderu).
Inne ulepszenia
W nowej wersji pracowaliśmy nad innymi ulepszeniami, które miały wpływ na wydajność. Zapisywanie drzewa zostało wykonane przyrostowo, co pozwala na zapisanie do pliku tylko najnowszych zmian.Yandex.Disk używa skrótów sha256 i MD5 do sprawdzania integralności plików, wykrywania fragmentów i deduplikacji plików w wewnętrznej bazie danych. Ponieważ to zadanie mocno obciąża procesor, w nowej wersji implementacja obliczeń skrótu została znacznie zoptymalizowana. Szybkość otrzymania podsumowania pliku jest około dwukrotnie większa.
Aby przywrócić pliki z kopii zapasowej utworzonej po utworzeniu kopii zapasowej obrazu systemu, wykonaj następujące kroki: Funkcje tworzenia kopii zapasowych, przywracania i synchronizacji towarzyszą intuicyjnemu kreatorowi instalacji. Użyj funkcji tworzenia kopii zapasowej, aby uzyskać dostęp do następujących trybów tworzenia kopii zapasowych.
Usługi w chmurze obsługiwane przez tworzenie kopii zapasowych. Podczas tworzenia kopii zapasowej w celu uzyskania dostępu prywatnego upewnij się, że użytkownik ma dostęp do udostępniony folder. W sekcji „Kopia zapasowa”. Przywróć kopię zapasową wykonaną na stronie kopii zapasowej.
Ryciny
Synchronizacja unikalnych 20 000 plików o wielkości 10 KBObliczanie podsumowań unikalnych 20 000 plików o wielkości 10kb (indeksowanie)
Począwszy od 20 000 zsynchronizowanych plików o wielkości 10 KB
Prześlij 1 Gb. Połączenie Wi-Fi 10 Mb / s
Co się stało
Przykłady to pokazują nowa wersja Oprogramowanie Yandex.Disk zużywa około 3 razy mniej pamięci RAM i około 2 razy mniej obciążenia procesora. Przetwarzanie drobnych zmian nie zwiększa ilości używanej pamięci.W wyniku wprowadzonych zmian znacznie wzrosła liczba plików, z którymi program radzi sobie bez problemu. W wersji Windows 300 000, a Mac OS X 900 000 plików.
Przykłady tworzenia kopii zapasowych, synchronizacji i odzyskiwania
Usługi w chmurze obsługiwane przez synchronizację. Jeśli kilka zadań zostanie przypisanych jednocześnie lub uruchomionych ręcznie, menedżer zapisuje je w kolejce. Właściciel przechowuje ważne pliki w swoim osobistym udziale. Oba systemy są podłączone do tego samego sieć lokalna. Tworzenie kopii zapasowej zawartości sieciowego urządzenia pamięci masowej używanego poza siecią lokalną. Docelowe urządzenie magazynujące może być również kompatybilnym urządzeniem magazynującym innej firmy.
Tworzenie kopii zapasowej treści w usłudze chmurowej
Ważne zdjęcie z jego osobistej wymiany zostało przypadkowo usunięte.W poprzednich dwóch artykułach I skonfigurowany LAMP na VPS i przykręciłem do niego nginx. Następną rzeczą, o której zaczynasz myśleć od razu, jest to, jak to wszystko stracić. Oznacza to, że chodzi o tworzenie kopii zapasowych.
Porozmawiajmy w kolejności: co, gdzie i jak wykonać kopię zapasową.
co
- Wszystkie konfiguracje, które starannie edytowałeś ( / etc)
- Wszystkie pliki użytkownika ( / Dom, / root)
- Bazy danych (będziemy mieli na myśli MySQL)
Gdzie
Dzisiaj wszystko idzie w „chmury”. Chcę umieścić kopie zapasowe w tym samym miejscu.
Na szczęście właściciel tworzy kopię zapasową swoich danych w innym systemie pamięci masowej. Przywróć kopię zapasową, aby przywrócić wcześniejszą wersję tego zasobu, w tym utracony plik. Zaloguj się do docelowego urządzenia magazynującego z komputera i znajdź brakujący plik. Na przykład możesz pobrać plik z usługi pamięci masowej w chmurze, która udostępnia kopię zapasową chmury osobistej. Ważne: czas wymagany do wykonania pierwszego zadania tworzenia kopii zapasowej może się różnić w zależności od ilości danych i szybkości sieci, co może potrwać kilka godzin lub nawet dni, aby wykonać kopię zapasową witryny lub w chmurze.
Yandex.Disk okazał się bardzo interesującą opcją przechowywania kopii zapasowej. Ma kilka zalet:
- Darmowe 10 GB
- Znajduje się w Rosji, a pliki są na niego bardzo szybko przelewane
- Potrafi pracować na protokole WebDAV, który pozwala na pobieranie danych z konsoli za pomocą polecenia curl
w jaki sposób
Oto recepta. Zaloguj się jako root i utwórz skrypt:
Kliknij „Dodaj kopię zapasową”, aby uruchomić kreatora kopii zapasowej. Wybierz „Kopia zapasowa”. . Postępuj zgodnie z instrukcjami Kreatora kopii zapasowej, aby wykonać jeden z następujących typów kopii zapasowych. W poniższych sekcjach. Stół poniżej.
Dzięki tym zoptymalizowanym formatom możesz tworzyć przyrostowe kopie zapasowe. Ten typ kopii zapasowej umożliwia tworzenie kopii zapasowych nowych lub zmienionych plików z poprzedniej kopii zapasowej. Jeśli format nie jest zoptymalizowany, zawsze należy wykonać pełną kopię zapasową za każdym razem, gdy wykonujesz nowe zadanie, w którym to przypadku wszystkie elementy w źródle są kopiowane przy każdym wykonaniu nowego zadania.
Chmod 0700 backup-now.sh
Tekst skryptu będzie wyglądał mniej więcej tak:
#! / bin / bash SERVER_NAME \u003d "server1" TIME \u003d `data +% Y-% b` FS_FILE \u003d / tmp / $ SERVER_NAME-fs. $ TIME.tar.gz MYSQL_FILE \u003d / tmp / $ SERVER_NAME-mysql. $ TIME .sql.gz # Archiwizacja systemu plików tar -czf $ FS_FILE / etc / root / home # Archiwizacja baz danych mysqldump -u root --password \u003d qwerty --all-databases | gzip\u003e $ MYSQL_FILE # Przesyłanie do curl chmury - użytkownik UŻYTKOWNIK: HASŁO -T "($ FS_FILE, $ MYSQL_FILE)" https://webdav.yandex.ru/ # Oczyszczanie rozłącz $ FS_FILE rozłącz $ $ MYSQL_FILE
Za pierwszym razem lepiej jest uruchamiać polecenia pojedynczo, komentując resztę. Jeśli wszystko pójdzie dobrze, na twoim dysku Yandex.Disk pojawią się dwa archiwa.
Teraz do automatyzacji musisz dodać dowiązanie symboliczne do backup-now.sh w /etc/cron.daily (lub /etc/cron.weekly). Pamiętaj tylko, że w niektórych systemach (w szczególności w Debianie) dowiązanie symboliczne należy usunąć z rozszerzenia ().
Zmienna $ TIME jest wybrana, aby gromadzić kopie zapasowe z ostatniego dnia każdego miesiąca. Jeśli nie chcesz zaśmiecać chmury, możesz to usunąć ze skryptu, ale praktyka pokazuje, że stare kopie mogą być przydatne. Konieczne będzie tylko okresowe usuwanie śmieci.
A jeśli nie chcę Yandex.Disk?
Oczywiście można przesłać do dowolnego zasobu obsługującego WebDAV. Istnieją usługi zapewniające dostęp WebDAV do Dropbox lub Google Drive (na przykład Otixo, SMEStorage, DropDAV). Plotka głosi, że SkyDrive działa za pośrednictwem WebDAV. Istnieje również nadzieja, że \u200b\u200bwsparcie pojawi się w Dropbox po wyjęciu z pudełka.
P.S. Szyfrowanie archiwum za pomocą GnuPG
Ponieważ kopie zapasowe zawierają wiele tajnych informacji (hasła, dane), warto je zaszyfrować:
GPG_COMMAND \u003d "gpg -c -z 0 --batch --passphrase XXXXXXXXXX" FS_FILE \u003d / tmp / $ SERVER_NAME-fs. $ TIME.tar.gz.gpg MYSQL_FILE \u003d / tmp / $ SERVER_NAME-mysql. $ TIME.sql. gz.gpg # Archiwizacja systemu plików tar -cz / etc / root / home | $ GPG_COMMAND\u003e $ FS_FILE # Archiwizacja baz danych mysqldump -u root - hasło - qwerty - wszystkie bazy danych | gzip | $ GPG_COMMAND\u003e $ MYSQL_FILE. . .



