Автоматическое копирование на яндекс диск. Бэкап данных на Яндекс.Диск с новым Handy Backup. Функции классического приложения встроены в Windows
Яндекс.Диск - один из немногих сервисов Яндекса, частью которого является программное обеспечение для десктопа. И одна из самых важных его составляющих - алгоритм синхронизации локальных файлов с их копией в облаке. Недавно нам пришлось его полностью поменять. Если старая версия с трудом переваривала даже несколько десятков тысяч файлов и к тому же не достаточно быстро реагировала на некоторые «сложные» действия пользователя, то новая, используя те же ресурсы, справляется с сотнями тысяч файлов.
Вы можете загрузить его из магазина игр и дать ему попробовать бесплатно, не заплатив ни копейки. Эта услуга действительно очень проста в использовании. Он поставляется с некоторыми дополнительными функциями, а также из них - фотокопия, которая позволяет загружать любую фотографию, которую вы берете с телефона, в облако автоматически, а другая - совместное использование папок, что позволяет вам обмениваться любой папкой с кем-либо. Благодаря своим мощным серверам никогда не удастся загрузить ваши файлы.
Он позволяет просматривать историю изменений в ваших документах и делиться с вашим другом и позволять им редактировать. Эта услуга, если она очень хороша для тех пользователей, которые хотят загружать каждый момент, когда они захватывают и просматривают их на своем ноутбуке на настольном компьютере или ноутбуке мгновенно. Это лучшее в использовании, потому что он очень прост в использовании для каждого пользователя.
В этом посте я расскажу, почему так получилось: чего мы не смогли предвидеть, когда придумывали первую версию ПО Яндекс.Диска, и как создавали новую.
Прежде всего, о самой задаче синхронизации. Технически говоря, она состоит в том, чтобы в папке Яндекс.Диска на компьютере пользователя и в облаке был один и тот же набор файлов. То есть такие действия пользователя, как переименование, удаление, копирование, добавление и изменение файлов, должны синхронизироваться с облаком автоматически.
Этого хранилища достаточно для хранения и обмена фотографиями и видео. Независимо от того, что вы загружаете в облако, используя мега, все это будет бесплатным и зашифрованным, а ключ остается у пользователей. Это позволяет вам синхронизировать изображения с камеры непосредственно с мега облаком. Но если вам нужно больше места для хранения, есть некоторые планы. В этом приложении есть некоторые ошибки, но большинство пользователей с удовольствием используют это приложение.
Каждый веб-мастер должен иметь несколько резервных копий своего веб-сайта, если что-то пойдет не так. Таким образом, вам нужно сделать резервную копию всех своих файлов, а также базы данных, чтобы иметь полную копию вашего сайта. Тогда, какое лучшее место для сохранения этого дублирования?
Почему это не так просто, как кажется на первый взгляд?
Теоретически задача может показаться достаточно простой, но в реальности мы сталкиваемся с разными сложными ситуациями. Например, человек переименовал папку на своем компьютере, мы это детектировали и послали команду на бекенд. Однако никто из пользователей не ждет, пока бекенд подтвердит успешность переименования. Человек сразу открывает свою локально переименованную папку, создает в ней подпапку, и, к примеру, переносит в нее часть файлов. Мы попали в ситуацию, в которой невозможно сразу выполнить все необходимые операции синхронизации в облаке. Сначала надо дождаться завершения первой операции и только потом можно продолжать.Ситуация может стать еще сложнее, если с одним аккаунтом одновременно работают несколько пользователей или у них есть общая папка. А это случается достаточно часто в организациях, использующих Яндекс.Диск. Представьте себе, что в предыдущем примере в тот момент, когда мы получили от бекенда подтверждение первого переименования, другой пользователь берет и переименовывает эту папку еще раз. В этом случае опять нельзя сразу выполнить действия, которые уже совершил первый пользователь у себя на компьютере. Папка, в которой он работал локально, на бекенде в это время уже называется по-другому.
Диск - это облачный сервис, особенно популярный среди российских пользователей. 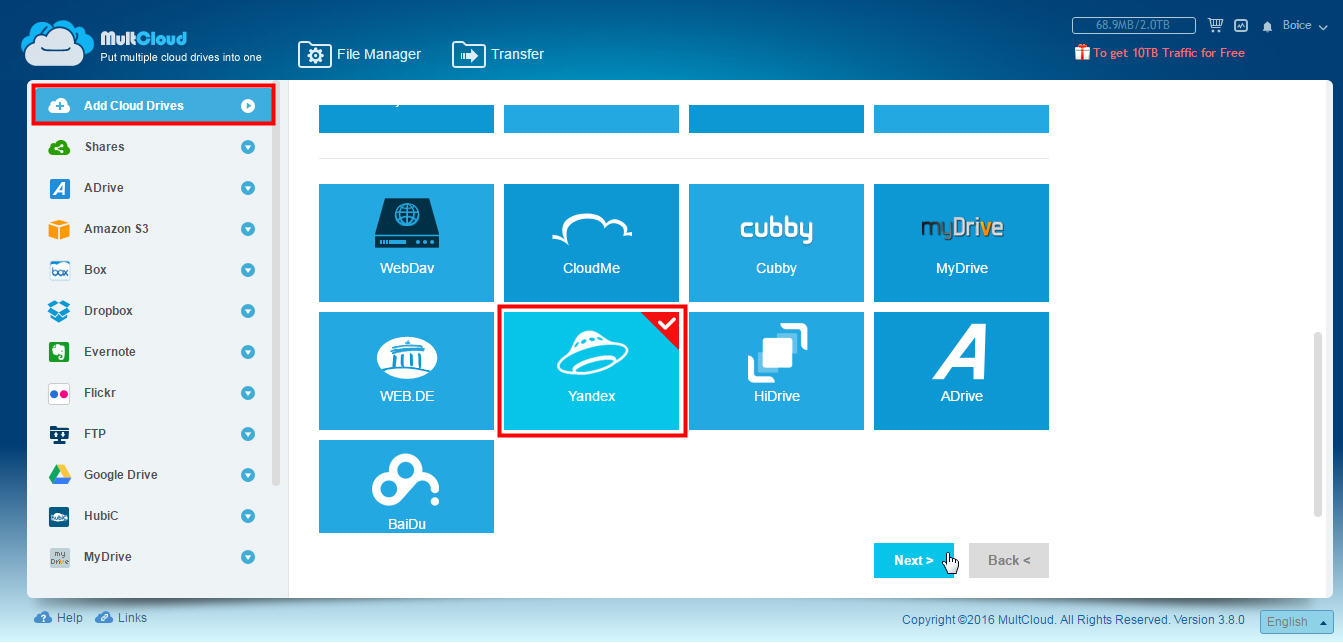
Существует множество вариантов, но каждый может быть использован, как угодно. Когда у вас будет все готово, вы увидите, что в столбце слева будут перечислены различные службы. Если вы нажмете кого-нибудь или вы нажмете на маленькую стрелку справа, вы увидите папки, которые находятся в каждой. Конечно, вы можете увидеть, что они содержат, дважды щелкнув по ним. Вы также можете просмотреть предлагаемые варианты, используя меню правой кнопки мыши, отображаемое в папке или файле.
Бывают случаи, когда файл на компьютере пользователя нельзя назвать так же, как он называется в облаке. Это может произойти, если в имени есть символ, который не может использоваться локальной файловой системой, или в том случае, когда пользователя приглашают в общую папку, а у него есть своя папка с таким именем. В таких случаях нам приходится использовать локальные псевдонимы и отслеживать их связь с объектами в облаке.
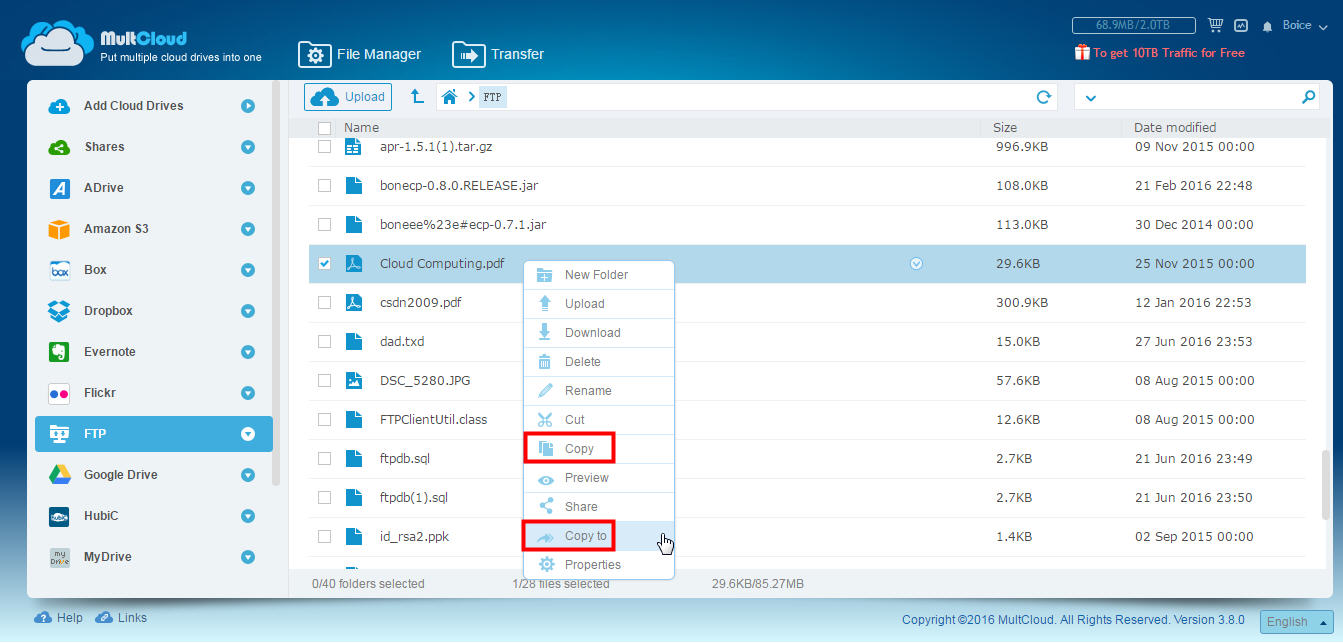
Чтобы скопировать папку или файл из проводника документов, щелкните его правой кнопкой мыши и нажмите «Копировать». Немедленно запустите окно с услугами хранения, доступными для копирования, кроме того, у нас будет возможность выбрать несколько пунктов назначения без каких-либо осложнений. Процесс настолько прост, что он похож на операцию, выполняемую непосредственно из службы хранения.
Запланированные резервные копии
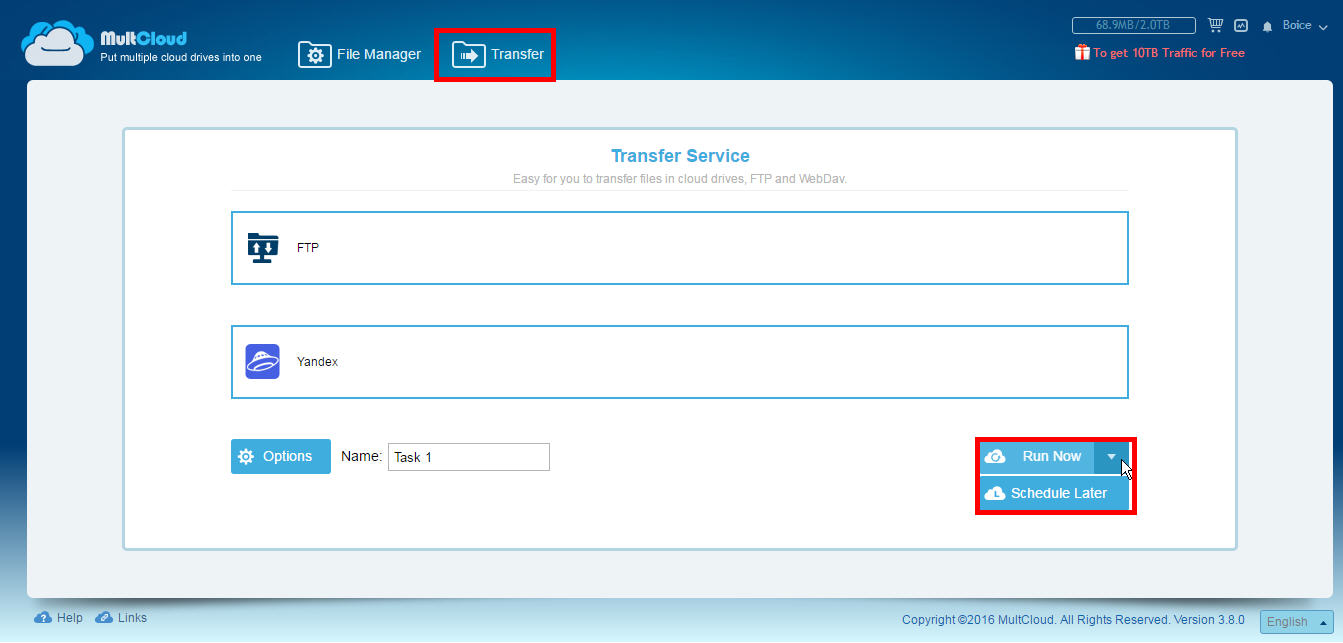
Вы должны подумать, что при создании копии исходный файл останется в другой службе, потому что если вы не хотите дублировать, вы должны удалить исходный файл, не беспокоясь о его удалении. Другим способом переноса файлов из одного места в другое, а также полезным для резервного копирования, является использование кнопки «Верхняя передача», которая позволяет вам выбрать каталог для копирования с одной службы на другую, в дополнение к настройке более продвинутых параметров, таких как программирование операцию, перезаписать, если есть изменения, переименовать, отправить уведомления по электронной почте и включить или исключить файлы.
Прошлая версия алгоритма
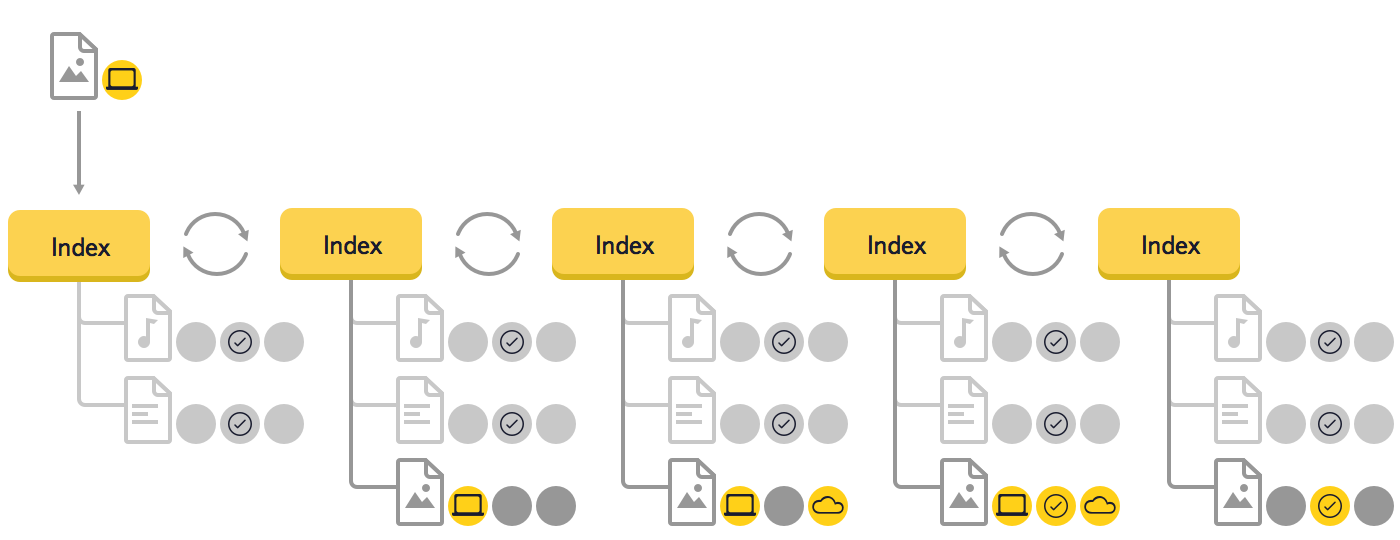
В прошлой версии десктопного ПО Яндекс.Диска для поиска изменений использовался алгоритм сравнения деревьев. Любое другое решение на тот момент не позволяло реализовать поиск перемещений и переименований, так как бэкэнд не имел уникальных идентификаторов объектов.В этой версии алгоритма мы использовали три основных дерева: локальное (Local Index), облачное (Remote Index) и последнее синхронизированное (Stable Index). Кроме этого, чтобы предотвратить повторную генерацию уже поставленных в очередь операций синхронизации, использовались ещё два вспомогательных дерева: локальное ожидаемое и облачное ожидаемое (Expected Remote Index и Expected Local Index). В этих вспомогательных деревьях хранилось ожидаемое состояние локальной файловой системы и облака, после выполнения всех операций синхронизации, которые уже поставлены в очередь.
Параметры планирования позволяют выполнять операцию автоматически один раз, ежедневно в определенное время, еженедельно в определенные дни и время и ежемесячно в заданное время и дату. Чтобы увидеть ожидающие задачи, мы можем получить доступ к менеджеру с помощью кнопки, расположенной слева от нашего имени, вверху.
Теперь, когда вы знаете самый простой способ скопировать файлы с одного хранилища на другой или даже на сервер, забудьте повторно загрузить файлы для их загрузки или использования своего настольного клиента. Цель этого руководства состоит в том, что вы можете управлять своими различными службами без стресса.

Процедура сравнения деревьев в старом алгоритме выглядела следующим образом:
- Если локальное ожидаемое дерево и облачное ожидаемое дерево пусты, инициализируем их, копируя последнее синхронизированное дерево;
- Сравниваем локальное дерево с облачным ожидаемым и по результатам сравнения отдельных узлов добавляем в очередь операции синхронизации в облаке (создание коллекций, передача файлов в облако, перемещение и удаление в облаке);
- Для всех операций, которые поставлены в очередь на предыдущем шаге, фиксируем их будущий эффект в ожидаемом облачном дереве;
- Сравниваем облачное дерево с локальным ожидаемым и по результатам сравнения отдельных узлов добавляем в очередь операции синхронизации с локальной файловой системой (создание директорий, скачивание файлов из облака, перемещение и удаление локальных файлов и директорий);
- Для всех операций, которые поставлены в очередь на предыдущем шаге, фиксируем их будущий эффект в ожидаемом локальном дереве;
- Если в очередь попадают одновременные операции с одним и тем же файлом или директорией (например, передача файла в облако и скачивание этого же файла из облака), то фиксируем конфликт - файл изменился в двух местах;
- После того, как операция синхронизации выполнена в облаке или с локальной файловой системой, заносим её результат в последнее синхронизированное дерево;
- Когда очередь операций синхронизации становится пустой, удаляем локальное ожидаемое и облачное ожидаемое дерево. Синхронизация закончена, и они нам больше не понадобятся.
Почему нам пришлось придумывать новый алгоритм
Главными проблемами алгоритма сравнения деревьев стали большое потребление памяти и необходимость сравнения деревьев целиком даже при небольших изменениях, что приводило к большой нагрузке на процессор. Во время обработки изменений даже одного файла использование оперативной памяти возрастало примерно на 35%. Допустим, у пользователя было 20 000 файлов. Тогда при простом переименовании одного файла размером 10Кб потребление памяти вырастало скачкообразно - со 116Мб до 167МБ.Также мы хотели увеличить максимальное количество файлов, с которым без проблем может работать пользователь. Несколько десятков и даже сотен тысяч файлов может оказаться, к примеру, у фотографа, который хранит в Яндекс.Диске результаты фотосессий. Эта задача стала особенно актуальной, когда у людей появилась возможность купить дополнительное место на Яндекс.Диске.
Существует несколько способов резервного копирования вашего компьютера. Например, не сохраняйте резервные копии файлов в разделе восстановления. Всегда держите носитель, который вы используете для резервного копирования, в безопасном месте, чтобы предотвратить доступ к вашим файлам неавторизованных лиц; рекомендуется использовать огнестойкое место, отличное от оборудования.
Чтобы создать системный образ
Вы также можете рассмотреть возможность шифрования данных из резервной копии.
Изображения системы содержат всю информацию о компьютере в определенном состоянии
Поддерживайте различные версии системных изображений. Вы можете хранить несколько версий системных изображений. На внутренних и внешних жестких дисках старые системные изображения будут удалены, когда на диске закончится свободное пространство. Чтобы сохранить дисковое пространство, удалите старые системные изображения.В разработке тоже хотелось кое-что поменять. Отладка старой версии вызывала трудности, так как данные о состояниях одного элемента находились в разных деревьях.
К этому времени на бекенде появились id объектов, с помощью которых можно было более эффективно решить задачу обнаружения перемещений - ранее мы использовали пути.
Если вы сохраняете изображения системы в сетевом расположении, вы можете сохранять только самые последние изображения системы на каждом компьютере. Если у вас есть существующий системный образ компьютера и создать новый для одного и того же компьютера, новое изображение перезапишет существующее. Если вы хотите сохранить существующее изображение, вы можете скопировать его в другое место перед созданием нового образа системы, выполнив следующие шаги.
Создать точку восстановления
Выделите место расположения образа системы. . Вы можете использовать точку восстановления для восстановления системных файлов компьютера в более ранний момент времени. Восстановление системы автоматически создает точки восстановления каждую неделю и когда компьютер обнаруживает изменения, например, когда установлено приложение или драйвер.
Новый алгоритм
Мы решили изменить структуру хранения данных и заменить три дерева (Local Index, Remote Index, Stable Index) на одно, что должно было привести к снижению избыточности в главной структуре данных. Из-за того что ключом в дереве является путь к элементу файловой системы, в результате объединения значительно сократился объем используемой оперативной памяти.
Это способ создания точки восстановления. Чтобы выполнить поиск содержимого резервной копии, выберите «Поиск файлов» или «Поиск папок». Когда вы ищете папки, вы не можете видеть отдельные файлы в папке. . Если вы ищете файлы или папки, связанные с определенной учетной записью пользователя, вы можете улучшить результаты поиска, введя расположение файла или папки в поле поиска.
Восстановите резервную копию, сделанную на другом компьютере
Найдите файлы, которые были восстановлены из резервной копии, сделанной на другом компьютере
Если вы восстанавливаете файлы из резервной копии, выполненной на другом компьютере, файлы будут восстановлены в папку под именем пользователя, которое использовалось для создания резервной копии. Если имена пользователей различны, вам нужно будет прокрутить список до папки, в которой будут восстановлены файлы.Еще мы отказались от использования вспомогательных деревьев во время синхронизации, потому что каждый элемент дерева в новой версии хранит все нужные данные. Это изменение структуры сильно упростило отладку кода.
Так как мы понимали, что это серьезное изменение, то создали прототип, подтвердивший эффективность нового решения. Рассмотрим на примере, как меняются данные в дереве во время синхронизации нового файла.
- После того как пользователь добавил в папку Диска новый файл, программа обнаружила его и добавила в дерево новый элемент. У этого элемента известно только одно состояние – local. Так как stable и remote состояния отсутствуют, память под них не выделяется;
- Программа выполняет upload файла. Из облака приходит push, подтверждающий появление нового файла, и в дерево добавляется remote состояние;
- Состояния local и remote сравниваются. Так как они совпадают, добавляется stable состояние;
- Состояния local и remote удаляются. Они больше не нужны, так как вся информация есть в stable.
Виртуальные машины и хранилища
Вы можете найти восстановленные файлы, выполнив следующие действия. Дважды щелкните папку имени пользователя, которое было использовано для создания резервной копии. Восстановленные файлы будут находиться в разных папках в зависимости от того, где они были изначально. Восстановите файлы из резервной копии после восстановления компьютера из резервной копии образа системы.
- Выберите кнопку «Пуск» и выберите «Компьютер».
- Дважды щелкните значок диска, где файлы были сохранены.
- Щелкните папку «Пользователи».
- Вы увидите папку для каждой учетной записи пользователя.
На этом примере видно, что в новом алгоритме синхронизации обрабатываются только те элементы и события, данные об изменениях в которых были получены от файловой системы или облака, а не всё дерево целиком, как это было ранее. При необходимости будут обработаны родительские или дочерние узлы (например, в случае перемещения папки).
Другие улучшения
В новой версии мы поработали и над другими улучшениями, повлиявшими на производительность. Сохранение дерева сделали инкрементальным, что позволяет записывать в файл только последние изменения.Яндекс.Диск использует дайджесты sha256 и MD5 для проверки целостности файлов, обнаружения изменившихся фрагментов и дедупликации файлов на бекенде. Так как эта задача сильно нагружает CPU, в новой версии реализация расчетов дайджеста была существенно оптимизирована. Скорость получения дайджеста файла увеличена примерно в два раза.
Чтобы восстановить файлы из резервной копии, созданной после создания резервной копии образа системы, выполните следующие действия. Функции резервного копирования, восстановления и синхронизации сопровождаются интуитивно понятным мастером установки. Используйте функцию резервного копирования для доступа к следующим режимам резервного копирования.
Облачные сервисы, поддерживаемые функцией резервного копирования. Когда вы создаете резервную копию для частного доступа, убедитесь, что пользователь имеет доступ к общей папке. В разделе «Резервное копирование». Восстановите резервную копию, выполненную на странице резервного копирования.
Цифры
Синхронизация уникальных 20000 файлов по 10КбВычисление дайджестов уникальных 20000 файлов по 10кб (индексация)
Запуск с 20000 синхронизированных файлов по 10Кб
Upload 1Gb. Соединение Wi-Fi 10 МБит
Что получилось
Из примеров видно, что новая версия ПО Яндекс.Диска использует примерно в 3 раза меньше оперативной памяти и примерно в 2 раза меньше нагружает CPU. Обработка мелких изменений не приводит к увеличению объема используемой памяти.В результате проделанных изменений существенно увеличилось количество файлов, с которым без проблем справляется программа. В версии для Windows – 300 000, а на Mac OS X - 900 000 файлов.
Примеры резервного копирования, синхронизации и восстановления
Облачные сервисы, поддерживаемые функцией синхронизации. Если одновременно назначено несколько задач или запускается вручную, менеджер сохраняет их в очереди. Владелец хранит важные файлы в своей личной доле. Обе системы подключены к одной и той же локальной сети. Резервное копирование содержимого на сетевое устройство хранения, которое используется вне локальной сети. Целевое запоминающее устройство может также быть совместимым сторонним устройством хранения.
Резервное копирование контента в облачную службу
Важная картина его личного обмена была случайно удалена.В предыдущих двух статьях я настраивал LAMP на VPS и прикручивал к нему nginx . Следующее, о чем сразу начинаешь думать — как бы все это не потерять. То есть речь заходит о резервном копировании.
Обсудим по порядку: что, куда и как бэкапить.
Что
- Все конфиги, которые вы с кропотливо редактировали (/etc )
- Все пользовательские файлы (/home , /root )
- Базы данных (будем иметь в виду MySQL)
Куда
Нынче всё уходит в «облака». Резервные копии хочется складывать туда же.
К счастью, владелец резервирует свои данные на другой системе хранения. Восстановите резервную копию, чтобы восстановить более раннюю версию этого ресурса, включая потерянный файл. Войдите в конечное запоминающее устройство с компьютера и найдите отсутствующий файл. Например, вы можете получить файл из службы облачных хранилищ, на которой размещена резервная копия вашего личного облака. Важно: время, необходимое для выполнения первой задачи резервного копирования, может варьироваться в зависимости от объема данных и скорости вашей сети, что может потребовать нескольких часов или даже дней для резервного копирования сайта или в Облаке.
Весьма интересным вариантом для хранения бэкапа оказался Яндекс.Диск . У него есть несколько преимуществ:
- Бесплатные 10 Гб
- Он находится в России, и файлы очень быстро на него заливаются
- Умеет работать по протоколу WebDAV, что позволяет загружать на него данные из консоли с помощью команды curl
Как
Вот рецепт. Логинимся root-ом и создаем скрипт:
Нажмите «Добавить резервное копирование», чтобы запустить мастер резервного копирования. Выберите «Резервное копирование». . Следуйте инструкциям в Мастере резервного копирования, чтобы выполнить один из следующих типов резервного копирования. В следующих разделах. Таблицу ниже.
С помощью этих оптимизированных форматов вы можете выполнять инкрементное резервное копирование. Этот тип резервного копирования позволяет создавать резервные копии новых или измененных файлов из предыдущей резервной копии. Если формат не оптимизирован, вы всегда должны выполнять полную резервную копию каждый раз при выполнении новой задачи, и в этом случае все элементы в источнике копируются всякий раз, когда выполняется новая задача.
Chmod 0700 backup-now.sh
Текст скрипта будет примерно таким:
#!/bin/bash SERVER_NAME="server1" TIME=`date +%Y-%b` FS_FILE=/tmp/$SERVER_NAME-fs.$TIME.tar.gz MYSQL_FILE=/tmp/$SERVER_NAME-mysql.$TIME.sql.gz # Archiving filesystem tar -czf $FS_FILE /etc /root /home # Archiving databases mysqldump -u root --password=qwerty --all-databases | gzip > $MYSQL_FILE # Uploading to the cloud curl --user USER:PASSWORD -T "{$FS_FILE,$MYSQL_FILE}" https://webdav.yandex.ru/ # Cleanup unlink $FS_FILE unlink $MYSQL_FILE
Первый раз лучше запускать команды по одной, комментируя остальные. Если все пройдет хорошо, то в вашем Яндекс.Диске появятся два архива.
Теперь для автоматизации надо добавить симлинк на backup-now.sh в /etc/cron.daily (или /etc/cron.weekly). Только имейте в виду, что на некоторых системах (в частности, на Debian) у симлинка надо убрать расширение ().
Переменная $TIME подобрана так, что у вас будут скапливаться бекапы от последнего числа каждого месяца. Если не хотите захламлять облако, то это можно убрать из скрипта, однако практика показывает, что старые копии могут оказаться полезными. Просто надо будет периодически удалять старьё.
А если не хочу Яндекс.Диск ?
Очевидно, заливать можно на любой ресурс, поддерживающий WebDAV. Существуют сервисы, открывающие доступ по WebDAV к Dropbox или Google Drive (например, Otixo , SMEStorage , DropDAV). Ходят слухи, что SkyDrive работает через WebDAV. А также есть надежда , что поддержка появится в Дропбоксе из коробки.
P.S. Шифрование архивов с помощью GnuPG
Поскольку бекапы содержат кучу секретной информации (пароли, данные), то имеет смысл их шифровать:
GPG_COMMAND="gpg -c -z 0 --batch --passphrase XXXXXXXXXX" FS_FILE=/tmp/$SERVER_NAME-fs.$TIME.tar.gz.gpg MYSQL_FILE=/tmp/$SERVER_NAME-mysql.$TIME.sql.gz.gpg # Archiving filesystem tar -cz /etc /root /home | $GPG_COMMAND > $FS_FILE # Archiving databases mysqldump -u root --password=qwerty --all-databases | gzip | $GPG_COMMAND > $MYSQL_FILE . . .